
どうも2回生のハヤテとか大将とかそこらで呼ばれてるものです。
早速ですが、私最近感じてることがあるんです。(←唐突
それはですね..
RiGのみなさんAIとか機械学習とかに興味薄すぎませんか???(←うるさい(←余計なお世話
まあ、そういうわけでですね、夏休み明けのゲームショウでもですね、熱く語ったんですけどね、機械学習とかそこらの話をですね、簡単な例を使いながら少し書いていこうかなとですね、思うわけですよ。
え?言い方が鬱陶しい??

(ネタが古いという苦情は一切受け付けません)
始めに
というわけで今回書いていく内容は、pythonでOneMax問題を遺伝的アルゴリズム(GA)を用いて解いていきたいと思います。(知能勢はC言語でやってるよね?)
見なれない単語が突然たくさん出てきたと思ったあなた...ggrksと言いたいですが、簡単に説明していきます。
1.python
みんな大好きパ・イソンたん(^ω^)ペロペロ
C言語とかjavaと同じプログラミング言語の一つです。
最近ちまたで話題(当社比)になっている動的プログラミング言語で、特徴としては文法が優しいこと、実用的なライブラリが多いこと、計算速度が速いことが挙げられます。
とくに注目したいのが、文法が優しいことですかね。とにかくシンプルで読みやすい。if分などのブロックをインデントで管理するオフサイドルールを採用してるのも相まって可読性が高く、他人の書いたコードの理解がしやすいと思います。
2.OneMax問題
OneMax問題というのは、0,1でランダムに初期化されたビット配列を全て1にするという非常にシンプルな問題です。
例えば初期配列が
[0,1,1,0,0,0,0,1,0]
だったものをいろいろごちゃごちゃして
[1,1,1,1,1,1,1,1,1]
という理想配列に近づけていくということです。
因みにこの配列のことを一般的に個体といいます。また機械学習でよく聞く評価値というものは、今回の場合この配列内の数値によって決定されるということを理解しておくと少し今後の話が分かりやすいかもです。
3.遺伝的アルゴリズム(Genetic Algorithm,通称GA)
すいません、話すと長くなるので、ゲームショウで出した私のスライド見てください...。
本当にざっくり説明すると、先ほど話した個体を混ぜたり、変化させたりして次の個体を作り、その次の個体を前の世代の個体より良い個体(良い評価値を持っている)にしていくアルゴリズムです。(いろんな人から鉞投げられそう…)
説明も終わったのでじゃあやっていきましょう。
コーディング
pythonの基本的な文法に関しては解説しないので適宜ググってください(https://qiita.com/origer/items/8e2a3df3e043c04f316... とかいい感じにまとめてくれてるから参考にするといいかも)
また私自身pythonの一割程度しか理解してないので説明などでミスがあったら直接鉞投げてください。いろいろなサイトからパク…インスパイアしているので一貫性のない部分とか多々あるのでその点はご容赦ください。
(追記;コードは本当はフォーマットのコードを使用して書いてましたが、何故か改行を行ってくれないため、スクリーンショットにて代用してます。何か解決案がある方いらっしゃいましたら一報ください。)
GenomClass.py
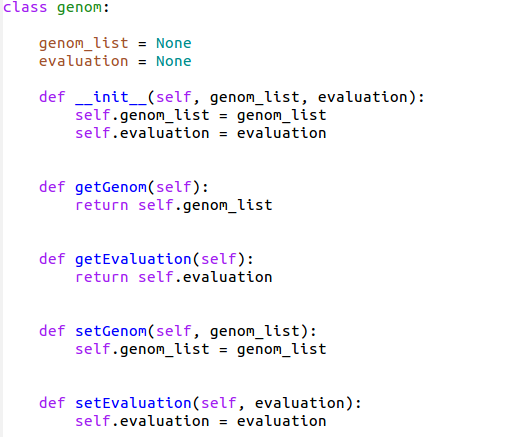
まず個体情報を保存するクラスを準備しましょう。
このClassをインスタンス変数として遺伝子情報と評価値情報を記憶させます。
setが値の代入、getが値の取得となっています。
次にmainのpyを作っていきましょう。
main.py(importとグローバル変数)
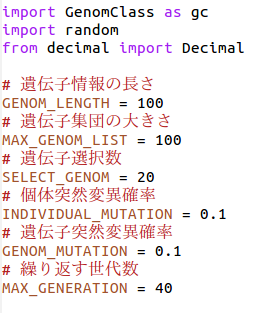
まずいわゆるグローバル変数として数値的設定を準備します。
今回の場合
遺伝子の長さ(個体のもつ配列内の数字の数):100
遺伝子を持つ個体の集団:100
その時点で最適解にエリート数(エリート個体=その世代内で優秀な評価値を持つ個体):20
エリートを交叉させて出す子孫個体数:40
纏めると
世代交代時内訳:エリート遺伝子20。子孫遺伝子40。エリート以外の現行遺伝子40。計100
またその他の準備データとして
個体突然変異確率:1%
遺伝子突然変異確率:1%(遺伝子一つの対しての突然変異確率)
世代交代数:40
としています。
次に各種関数を作っていきましょう。
関数自体はmain.py内に作っていきます。細かい説明はコード表示時にしますが、ざっくりとした説明を先にしておきます。
create_genom
引数で指定された数だけ遺伝子をランダムに生成します、値はgenomClassで返します
evaluation
個体から遺伝子情報を取り出して、評価値を作成します
select
個体集団から引数で指定された一定の数だけエリート集団を返します
crossover
引数から二つの個体を取得し、それから交叉を行い生成した子孫二つを配列に入れて返します
next_generation_gene_create
世代交代をします。現在の集団、エリート集団、子孫集団から作成します
mutation
引数から得られた確率をもとに突然変異処理をします。
ではやっていきましょう。
def create_genom(length):
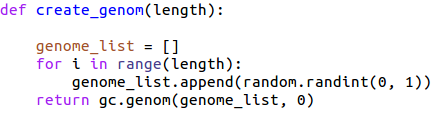
引数で指定された桁のランダムな遺伝子情報を生成し、格納したgenomclassで返しています。
パラメータ( length: 遺伝子情報の長さ return: 生成した個体集団genomClass )
小話ですが、パラメータをlenと省略せずlengthとしているのは、pythonの関数にリストのサイズを取得するlen関数というのがあるためです。(書いているときミスしました…)
def evaluation(gc):

評価関数です。
今回は全ての遺伝子が1の時を最適解としているため、合計した遺伝子と同じ長さの数となった場合を1として、0.00~1.00の間の数値を評価値としています。
パラメータ( gc: 評価を行うgenomClass return: 評価処理をしたgenomClassを返す )
def select(gc,elite_langth):

選択関数です。今回は、エリート選択というのをを行います。
評価が高い順番にソートを行った後、一定以上上位の個体をエリート個体として抽出し、その個体クラスを返しています。
パラメータ(gc: 選択を行うgenomClassの配列 elite_length: 選択するエリートの数 return: 選択処理をした一定のエリート個体のgenomClassを返す)
def crossover(gc_one, gc_second):
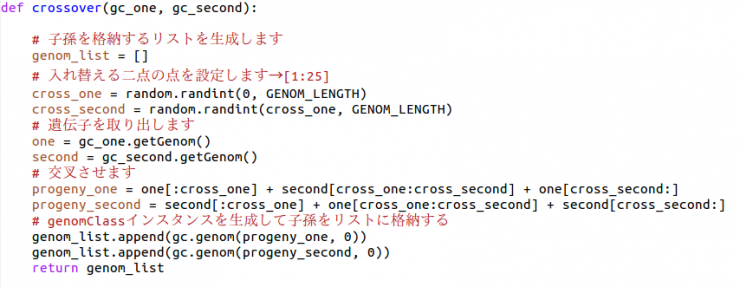
交叉関数です。二点交叉を行います。 今回の場合入れ替える個体の二点を設定したのち、その部分の配列数を丸々入れ替えるようにしています。
例(a個体の配列(10~15)[1,0,0,1,1] , b個体の配列(10~15)[0,1,0,0,1] (交叉)→ a個体の交叉後の配列(10~15)[0,1,0,0,1] , b個体の交叉後の配列(10~15)[1,0,0,1,1])
パラメータ( gc: 交叉させるgenomClassの配列 gc_one: 一つ目の個体 gc_second :二つ目の個体 return: 二つの子孫genomClassを格納したリスト返します)
def next_generation_gene_create(gc, gc_elite, gc_progeny):

世代交代処理関数です。最初に設定したデータをもとに、処理した個体集団を次世代の個体集団として処理していきます。
パラメータ( gc: 現行世代個体集団 gc_elite: 現行世代エリート集団 gc_progeny: 現行世代子孫集団 return: 次世代個体集団 )
def mutation(gc, individual_mutation, genom_mutation):
突然変異関数です。設定した突然変異確率及び遺伝子個々における突然変異確率をもとに突然変異を行っていきます。
今回行っている突然変異とは単純に、遺伝子が0であった場合1に、1であった場合0に入れ替える処理を行っています。
突然変異を行う理由についてですが、前にスライドでも話しましたが、GAは初期個体の混ぜ合わせによって行うため、その進化発展は初期個体のデータに左右されます。つまりどこかで頭打ちになる可能性が高いのです。
この現象の回避として、初期データに左右されない変化を行うために突然変異という処理を行う必要があります。(人間でも近親同士で子供を作った場合、悪い影響が出る可能性があるのと同じ理由です。)
パラメータ( gc: 突然変異をさせるgenomClass individual_mutation: 固定に対する突然変異確率 genom_mutation: 遺伝子一つ一つに対する突然変異確率 return: 突然変異処理をしたgenomClassを返します)
if name == 'main':
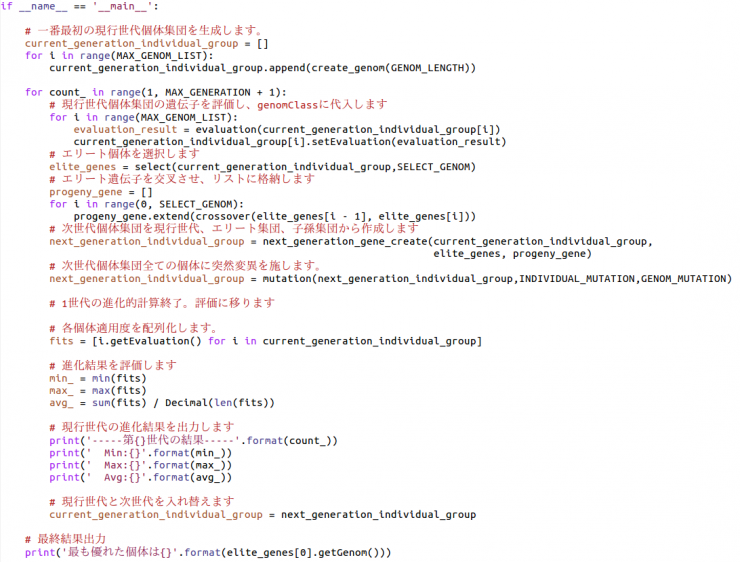
所謂main関数です。pythonはスクリプト言語であるため、スクリプトファイルとして他のプログラムから再利用することができます。その為、main.pyを直接実行した場合のみmain関数内を実行し、それ以外の時は実行しないという処置が必要です。それを表しているのが「if__name__ =='__main__':」という一文になっています。(すいません簡略な説明なので詳しい説明が知りたい方は自分でググって下さい。)
main関数内では、今まで用意してきた関数を使ってGAを行っています。また、途中処理時、最終処理結果を表示するようにしています。
実行結果
では、今まで作ってきたコードを実際に実行してみましょう。
-----第1世代の結果----- Min:0.37 Max:0.62 Avg:0.4964
-----第2世代の結果----- Min:0.48 Max:0.63 Avg:0.5612
-----第3世代の結果----- Min:0.54 Max:0.68 Avg:0.5979
-----第4世代の結果----- Min:0.56 Max:0.7 Avg:0.6293
-----第5世代の結果----- Min:0.59 Max:0.73 Avg:0.6498
-----第6世代の結果----- Min:0.63 Max:0.74 Avg:0.6755
-----第7世代の結果----- Min:0.63 Max:0.75 Avg:0.6988
-----第8世代の結果----- Min:0.66 Max:0.78 Avg:0.7198
-----第9世代の結果----- Min:0.67 Max:0.78 Avg:0.7402
-----第10世代の結果----- Min:0.7 Max:0.79 Avg:0.7536
以下11~38世代は略
-----第39世代の結果----- Min:0.77 Max:0.89 Avg:0.8766
-----第40世代の結果----- Min:0.83 Max:0.9 Avg:0.8791
最も優れた個体は
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1]
実行結果から分かる通り、最初世代の最大適用度が0.62に対して40世代目の最大適用度は0.90、要するに最初は1の数が最大でも62/100だったものが、40世代目では90/100となっていることが分かりますね。
つまり、GAを行うことによってより良い個体を作ることが出来たということが分かると思います。
まとめとか
さて、長々とやってきましたがどうだったでしょうか?(←長い(わかりにくい(結局何が言いたいか分からないetc...)
読んでくれた方の怨嗟の声が聞こえるようですが、結局何が言いたかったのかというと、機械学習とかって実際にやってみると実はやってることは単純なことなんだよってことを言いたかったんです。
今回やったことも私の説明下手抜いてもやってることはそんなに難しくなかったと思います。(難しかったって人は私が悪いのでそこは平にご容赦を)
もちろん、今回は単純な問題でしたが、例えばゲームのAIをより賢くしたいとか、より強いAIを作りたいとか、そういうときでもやってることは今回やったことと大差ないんです。
学習方法とか、これを用いたもっと実践的なことだとか、突き詰めていくと回帰関数とか損失関数だとかいろいろ難しいことも出てきますが、そんなのはやってからぶつかればいいんじゃないのかなと思います。
もし、食わず嫌いとか難しいって印象だけで、興味あるのにやれないって人がいたらよかったらこれを機にちょっと勉強して見て欲しいなぁと、AIとか機械学習とかそういうのにロマンを感じる私としては思います。
あと、こういうのやってるとただの配列の数字なのに、賢くなったなぁとかよくわからない愛情とか、そういう変な性癖に目覚めることがあるのでご注意を。(私は育成ゲームやってる感じで楽しいんですけどね。)
では、最後に
pythonはいいぞ!!!(pythonおじさん並感)
明日は、まいけみ君です。お楽しみに。